
我一度以为自己很懂Promise,直到前段时间尝试去实现Promise/A+规范时,才发现自己对Promise的理解还过于浅薄。在我按照Promise/A+规范去写具体代码实现的过程中,我经历了从“很懂”到“陌生”,再到“领会”的过山车式的认知转变,对Promise有了更深刻的认识!
TL;DR:鉴于很多人不想看长文,这里直接给出我写的Promise/A+规范的Javascript实现。
- github仓库:promises-aplus-robin(顺手点个star就更好了)
- 源码
- 源码注释版
promises-tests测试用例是全部通过的。
Promise源于现实世界
Promise直译过来就是承诺,最新的红宝书已经将其翻译为期约。当然,这都不重要,程序员之间只要一个眼神就懂了。

许下承诺
作为打工人,我们不可避免地会接到各种饼,比如口头吹捧的饼、升值加薪的饼、股权激励的饼……
有些饼马上就兑现了,比如口头褒奖,因为它本身没有给企业带来什么成本;有些饼却关乎企业实际利益,它们可能未来可期,也可能猴年马月,或是无疾而终,又或者直接宣告画饼失败。
画饼这个动作,于Javascript而言,就是创建一个Promise实例:
1 | const bing = new Promise((resolve, reject) => { |
Promise跟这些饼很像,分为三种状态:
- pending: 饼已画好,坐等实现。
- fulfilled: 饼真的实现了,走上人生巅峰。
- rejected: 不好意思,画饼失败,emmm…
订阅承诺
有人画饼,自然有人接饼。所谓“接饼”,就是对于这张饼的可能性做下设想。如果饼真的实现了,鄙人将别墅靠海;如果饼失败了,本打工仔以泪洗面。

转换成Promise中的概念,这是一种订阅的模式,成功和失败的情况我们都要订阅,并作出反应。订阅是通过then,catch等方法实现的。
1 | // 通过then方法进行订阅 |
链式传播
众所周知,老板可以给高层或领导们画饼,而领导们拿着老板画的饼,也必须给底下员工继续画饼,让打工人们鸡血不停,这样大家的饼才都有可能兑现。
这种自上而下发饼的行为与Promise的链式调用在思路上不谋而合。
1 | bossBing.then( |
总体来说,Promise与现实世界的承诺还是挺相似的。

而Promise在具体实现上还有很多细节,比如异步处理的细节,Resolution算法,等等,这些在后面都会讲到。下面我会从自己对Promise的第一印象讲起,继而过渡到对宏任务与微任务的认识,最终揭开Promise/A+规范的神秘面纱。
初识Promise
还记得最早接触Promise的时候,我感觉能把ajax过程封装起来就挺“厉害”了。那个时候对Promise的印象大概就是:优雅的异步封装,不再需要写高耦合的callback。
这里临时手撸一个简单的ajax封装作为示例说明:
1 | function isObject(val) { |
以上代码封装了ajax的主要过程,而其他很多细节和各种场景覆盖就不是几十行代码能说完的。不过我们可以看到,Promise封装的核心就是:
- 封装一个函数,将包含异步过程的代码包裹在构造Promise的executor中,所封装的函数最后需要return这个Promise实例。
- Promise有三种状态,Pending, Fulfilled, Rejected。而
resolve(),reject()是状态转移的触发器。 - 确定状态转移的条件,在本例中,我们认为ajax响应且状态码为200时,请求成功(执行
resolve()),否则请求失败(执行reject())。
ps: 实际业务中,除了判断HTTP状态码,我们还会另外判断内部错误码(业务系统中前后端约定的状态code)。
实际上现在有了axios这类的解决方案,我们也不会轻易选择自行封装ajax,不鼓励重复造这种基础且重要的轮子,更别说有些场景我们往往难以考虑周全。当然,在时间允许的情况下,可以学习其源码实现。
宏任务与微任务
要理解Promise/A+规范,必须先溯本求源,Promise与微任务息息相关,所以我们有必要先对宏任务和微任务有个基本认识。
在很长一段时间里,我都没有太多去关注宏任务(Task)与微任务(Microtask)。甚至有一段时间,我觉得setTimeout(fn, 0)在操作动态生成的DOM元素时非常好用,然而并不知道其背后的原理,实质上这跟Task联系紧密。
1 | var button = document.createElement('button'); |
如果不使用setTimeout 0,focus()会没有效果。
那么,什么是宏任务和微任务呢?我们慢慢来揭开答案。
现代浏览器采用多进程架构,这一点可以参考Inside look at modern web browser。而和我们前端关系最紧密的就是其中的Renderer Process,Javascript便是运行在Renderer Process的Main Thread中。
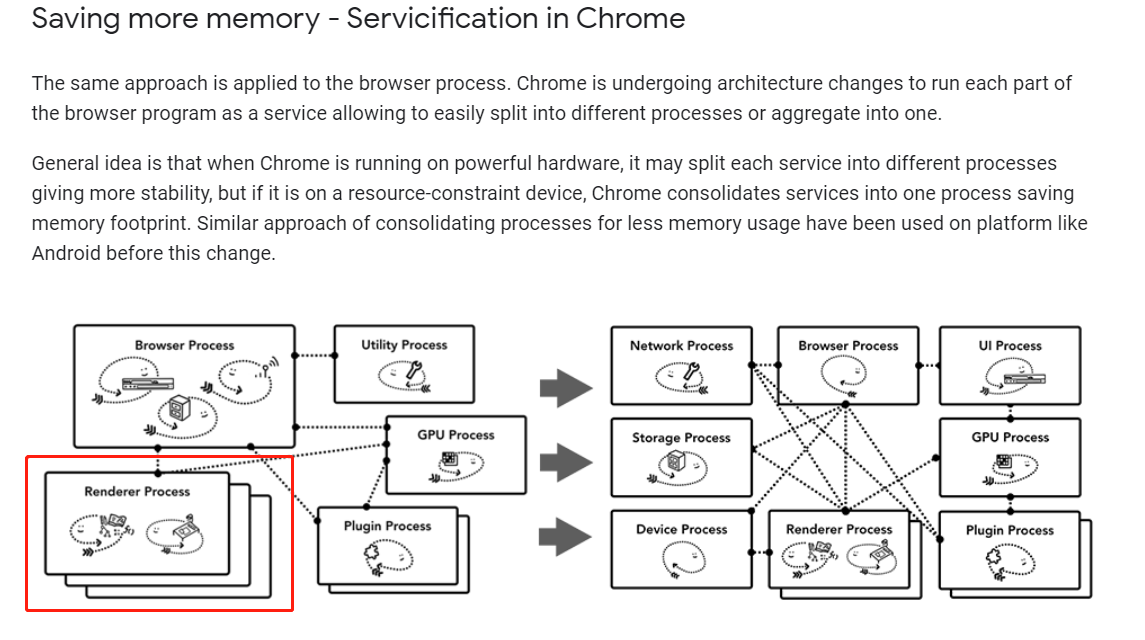
Renderer: Controls anything inside of the tab where a website is displayed.
渲染进程控制了展示在Tab页中的网页的一切事情。可以理解为渲染进程就是专门为具体的某个网页服务的。
我们知道,Javascript可以直接与界面交互。假想一下,如果Javascript采用多线程策略,各个线程都能操作DOM,那最终的界面呈现到底以谁为准呢?这显然是存在矛盾的。因此,Javascript选择使用单线程模型的一个重要原因就是:为了保证用户界面的强一致性。
为了保证界面交互的连贯性和平滑度,Main Thread中,Javascript的执行和页面的渲染会交替执行(出于性能考虑,某些情况下,浏览器判断不需要执行界面渲染,会略过渲染的步骤)。目前大多数设备的屏幕刷新率为60次/秒,1帧大约是16.67ms,在这1帧的周期内,既要完成Javascript的执行,还要完成界面的渲染(if necessary),利用人眼的残影效应,让用户觉得界面交互是非常流畅的。
用一张图看看1帧的基本过程,引用自https://aerotwist.com/blog/the-anatomy-of-a-frame/

PS:requestIdleCallback是空闲回调,在1帧的末尾,如果还有时间富余,就会调用requestIdleCallback。注意不要在requestIdleCallback中修改DOM,或者读取布局信息导致触发Forced Synchronized Layout,否则会引发性能和体验问题。具体见Using requestIdleCallback。
我们知道,一个网页中的Render Process只有一个Main Thread,本质上来说,Javascript的任务在执行阶段都是按顺序执行,但是JS引擎在解析Javascript代码时,会把代码分为同步任务和异步任务。同步任务直接进入Main Thread执行;异步任务进入任务队列,并关联着一个异步回调。
在一个web app中,我们会写一些Javascript代码或者引用一些脚本,用作应用的初始化工作。在这些初始代码中,会按照顺序执行其中的同步代码。而在这些同步代码执行的过程中,会陆陆续续监听一些事件或者注册一些异步API(网络相关,IO相关,等等…)的回调,这些事件处理程序和回调就是异步任务,异步任务会进入任务队列,并且在接下来的Event Loop中被处理。
异步任务又分为Task和Microtask,各自有单独的数据结构和内存来维护。
用一个简单的例子来感受下:
1 | var a = 1; |
以上代码执行后,依次在控制台输出:
1 | a: 1 |
仔细一看也没什么难的,但是这背后发生的细节,还是有必要探究下。我们不妨先问自己几个问题,一起来看下吧。
Task和Microtask都有哪些?
- Tasks:
setTimeoutsetIntervalMessageChannel- I/0(文件,网络)相关API
- DOM事件监听:浏览器环境
setImmediate:Node环境,IE好像也支持(见caniuse数据)
- Microtasks:
requestAnimationFrame:浏览器环境MutationObserver:浏览器环境Promise.prototype.then,Promise.prototype.catch,Promise.prototype.finallyprocess.nextTick:Node环境queueMicrotask
requestAnimationFrame是不是微任务?
requestAnimationFrame简称rAF,经常被我们用来做动画效果,因为其回调函数执行频率与浏览器屏幕刷新频率保持一致,也就是我们通常说的它能实现60FPS的效果。在rAF被大范围应用前,我们经常使用setTimeout来处理动画。但是setTimeout在主线程繁忙时,不一定能及时地被调度,从而出现卡顿现象。
那么rAF属于宏任务或者微任务吗?其实很多网站都没有给出定义,包括MDN上也描述得非常简单。
我们不妨自己问问自己,rAF是宏任务吗?我想了一下,显然不是,rAF可以用来代替定时器动画,怎么能和定时器任务一样被Event Loop调度呢?
我又问了问自己,rAF是微任务吗?rAF的调用时机是在下一次浏览器重绘之前,这看起来和微任务的调用时机差不多,曾让我一度认为rAF是微任务,而实际上rAF也不是微任务。为什么这么说呢?请运行下这段代码。
1 | function recursionRaf() { |
你会发现,在无限递归的情况下,rAF回调正常执行,浏览器也可正常交互,没有出现阻塞的现象。
而如果rAF是微任务的话,则不会有这种待遇。不信你可以翻到后面一节内容「如果Microtask执行时又创建了Microtask,怎么处理?」。
所以,rAF的任务级别是很高的,拥有单独的队列维护。在浏览器1帧的周期内,rAF与Javascript执行,浏览器重绘是同一个Level的。(其实,大家在前面那张「解剖1帧」的图中也能看出来了。)
Task和Microtask各有1个队列?
最初,我认为既然浏览器区分了Task和Microtask,那就只要各自安排一个队列存储任务即可。事实上,Task根据task source的不同,安排了独立的队列。比如Dom事件属于Task,但是Dom事件有很多种类型,为了方便user agent细分Task并精细化地安排各种不同类型Task的处理优先级,甚至做一些优化工作,必须有一个task source来区分。同理,Microtask也有自己的microtask task source。
具体解释见HTML标准中的一段话:
Essentially, task sources are used within standards to separate logically-different types of tasks, which a user agent might wish to distinguish between. Task queues *are used by user agents to coalesce task sources within a given event loop。
Task和Microtask的消费机制是怎样的?
An event loop has one or more task queues. A task queue is a set of tasks.
javascript是事件驱动的,所以Event Loop是异步任务调度的核心。虽然我们一直说任务队列,但是Tasks在数据结构上不是队列(Queue),而是集合(Set)。在每一轮Event Loop中,会取出第一个runnable的Task(第一个可执行的Task,并不一定是顺序上的第一个Task)进入Main Thread执行,然后再检查Microtask队列并执行队列中所有Microtask。
说再多,都不如一张图直观,请看!
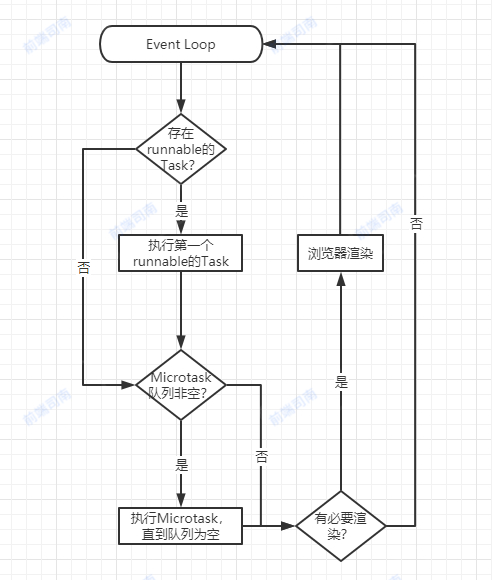
Task和Microtask什么时候进入相应队列?
回过头来看,我们一直在提这个概念“异步任务进入队列”,那么就有个疑问,Task和Microtask到底是什么时候进入相应的队列?我们重新来捋捋。异步任务有注册,进队列,回调被执行这三个关键行为。注册很好理解,代表这个任务被创建了;而回调被执行则代表着这个任务已经被主线程捞起并执行了。但是,在进队列这一行为上,宏任务和微任务的表现是不一样的。
宏任务进队列
对于Task而言,任务注册时就会进入队列,只是任务的状态还不是runnable,不具备被Event Loop捞起的条件。
我们先用Dom事件为例举个例子。
1 | document.body.addEventListener('click', function(e) { |
当addEventListener这行代码被执行时,任务就注册了,代表有一个用户点击事件相关的Task进入任务队列。那么这个宏任务什么时候才变成runnable呢?当然是用户点击发生并且信号传递到浏览器Render Process的Main Thread后,此时宏任务变成runnable状态,才可以被Event Loop捞起,进入Main Thread执行。
这里再举个例子,顺便解释下为什么setTimeout 0会有延迟。
1 | setTimeout(function() { |
执行setTimeout这行代码时,相应的宏任务就被注册了,并且Main Thread会告知定时器线程,“你定时0毫秒后给我一个消息”。定时器线程收到消息,发现只要等待0毫秒,立马就给Main Thread一个消息,“我这边已经过了0毫秒了”。Main Thread收到这个回复消息后,就把相应宏任务的状态置为runnable,这个宏任务就可以被Event Loop捞起了。
可以看到,经过这样一个线程间通信的过程,即便是延时0毫秒的定时器,其回调也并不是在真正意义上的0毫秒之后执行,因为通信过程就需要耗费时间。网上有个观点说setTimeout 0的响应时间最少是4ms,其实也是有依据的,不过也是有条件的。
HTML Living Standard: If nesting level is greater than 5, and timeout is less than 4, then set timeout to 4.
对于这种说法,我觉得自己有个概念就行,不同浏览器在实现规范的细节上肯定不一样,具体通信过程也不详,是不是4ms也不好说,关键是你有没有搞清楚这背后经历了什么。
微任务进队列
前面我们提到一个观点,执行完一个Task后,如果Microtask队列不为空,会把Microtask队列中所有的Microtask都取出来执行。我认为,Microtask不是在注册时就进入Microtask队列,因为Event Loop处理Microtask队列时,并不会判断Microtask的状态。反过来想,如果Microtask在注册时就进入Microtask队列,就会存在Microtask还未变为runnable状态就被执行的情况,这显然是不合理的。我的观点是,Microtask在变为runnable状态时才进入Microtask队列。
那么我们来分析下Microtask什么时候变成runnable状态,首先来看看Promise。
1 | var promise1 = new Promise((resolve, reject) => { |
读者们,我的第一个问题是,Promise的微任务什么时候被注册?new Promise的时候?还是什么时候?不妨来猜一猜!

答案是.then被执行的时候。(当然,还有.catch的情况,这里只是就这个例子说)。
那么Promise微任务的状态什么时候变成runnable呢?相信不少读者已经有了头绪了,没错,就是Promise状态发生转移的时候,在本例中也就是resolve(1)被执行的时候,Promise状态由pending转移为fulfilled。在resolve(1)执行后,这个Promise微任务就进入Microtask队列了,并且将在本次Event Loop中被执行。
基于这个例子,我们再来加深下难度。
1 | var promise1 = new Promise((resolve, reject) => { |
在这个例子中,Promise微任务的注册和进队列并不在同一次Event Loop。怎么说呢?在第一个Event Loop中,通过.then注册了微任务,但是我们可以发现,new Promise时,执行了一个setTimeout,这是相当于注册了一个宏任务。而resolve(1)必须在宏任务被执行时才会执行。很明显,两者中间隔了至少一次Event Loop。
如果能分析Promise微任务的过程,你自然就知道怎么分析ObserverMutation微任务的过程了,这里不再赘述。
如果Microtask执行时又创建了Microtask,怎么处理?
我们知道,一次Event Loop最多只执行一个runnable的Task,但是会执行Microtask队列中的所有Microtask。如果在执行Microtask时,又创建了新的Microtask,这个新的Microtask是在下次Event Loop中被执行吗?答案是否定的。微任务可以添加新的微任务到队列中,并在下一个任务开始执行之前且当前Event Loop结束之前执行完所有的微任务。请注意不要递归地创建微任务,否则会陷入死循环。
下面就是一个糟糕的示例。
1 | // bad case |
请不要轻易尝试,否则页面会卡死哦!(因为Microtask占着Main Thread不释放,浏览器渲染都没办法进行了)

为什么要区分Task和Microtask?
这是一个非常重要的问题。为什么不在执行完Task后,直接进行浏览器渲染这一步骤,而要再加上执行Microtask这一步呢?其实在前面的问题中已经解答过了。一次Event Loop只会消费一个宏任务,而微任务队列在被消费时有“继续上车”的机制,这就让开发者有了更多的想象力,对代码的控制力会更强。
做几道题热热身?
在冲击Promise/A+规范前,不妨先用几个习题来测试下自己对Promise的理解程度。
基本操作
1 | function mutationCallback(mutationRecords, observer) { |
这道题就不分析了,答案:mt2 mt1 mt3 t2 t1
浏览器不讲武德?
1 | Promise.resolve().then(() => { |
这道题据说是字节内部流出的一道题,说实话我刚看到的时候也是一头雾水。经过我在Chrome测试,得到的答案确实很有规律,就是:0 1 2 3 4 5 6。
先输出0,再输出1,我还能理解,为什么输出2和3后又突然跳到4呢,浏览器你不讲武德啊!
emm…我被戴上了痛苦面具!
那么这背后的执行顺序到底是怎样的呢?仔细分析下,你会发现还是有迹可循的。
老规矩,第一个问题,这道题的代码执行过程中,产生了多少个微任务?可能很多人认为是7个,但实际上应该是8个。
| 编号 | 注册时机 | 异步回调 |
|---|---|---|
| mt1 | .then() | console.log(0);return Promise.resolve(4); |
| mt2 | .then(res) | console.log(res) |
| mt3 | .then() | console.log(1); |
| mt4 | .then() | console.log(2); |
| mt5 | .then() | console.log(3); |
| mt6 | .then() | console.log(5); |
| mt7 | .then() | console.log(6); |
| mt8 | return Promise.resolve(4)执行并且execution context stack清空后,隐式注册 |
隐式回调(未体现在代码中),目的是让mt2变成runnable状态 |
- 同步任务执行,注册mt1~mt7七个微任务,此时execution context stack为空,并且mt1和mt3的状态变为runnable。JS引擎安排mt1和mt3进入Microtask队列(通过HostEnqueuePromiseJob实现)。
- Perform a microtask checkpoint,由于mt1和mt3是在同一次JS call中变为runnable的,所以mt1和mt3的回调先后进入execution context stack执行。
- mt1回调进入execution context stack执行,输出0,返回
Promise.resolve(4)。mt1出队列。由于mt1回调返回的是一个状态为fulfilled的Promise,所以之后JS引擎会安排一个job(job是ecma中的概念,等同于微任务的概念,这里先给它编号mt8),其回调目的是让mt2的状态变为fulfilled(前提是当前execution context stack is empty)。所以紧接着还是先执行mt3的回调。 - mt3回调进入execution context stack执行,输出1,mt4变为runnable状态,execution context stack is empty,mt3出队列。
- 由于此时mt4已经是runnable状态,JS引擎安排mt4进队列,接着JS引擎会安排mt8进队列。
- 接着,mt4回调进入execution context stack执行,输出2,mt5变为runnable,mt4出队列。JS引擎安排mt5进入Microtask队列。
- mt8回调执行,目的是让mt2变成runnable状态,mt8出队列。mt2进队列。
- mt5回调执行,输出3,mt6变为runnable,mt5出队列。mt6进队列。
- mt2回调执行,输出4,mt2出队列。
- mt6回调执行,输出5,mt7变为runnable,mt6出队列。mt7进队列。
- mt7回调执行,输出6,mt7出队列。执行完毕!总体来看,输出结果依次为:0 1 2 3 4 5 6。
对这块执行过程尚有疑问的朋友,可以先往下看看Promise/A+规范和ECMAScript262规范中关于Promise的约定,再回过头来思考,也欢迎留言与我交流!
经过我在Edge浏览器测试,结果是:0 1 2 4 3 5 6。可以看到,不同浏览器在实现Promise的主流程上是吻合的,但是在一些细枝末节上还有不一致的地方。实际应用中,我们只要注意规避这种问题即可。
实现Promise/A+
热身完毕,接下来就是直面大boss Promise/A+规范。Promise/A+规范列举了大大小小三十余条细则,一眼看过去还是挺晕的。
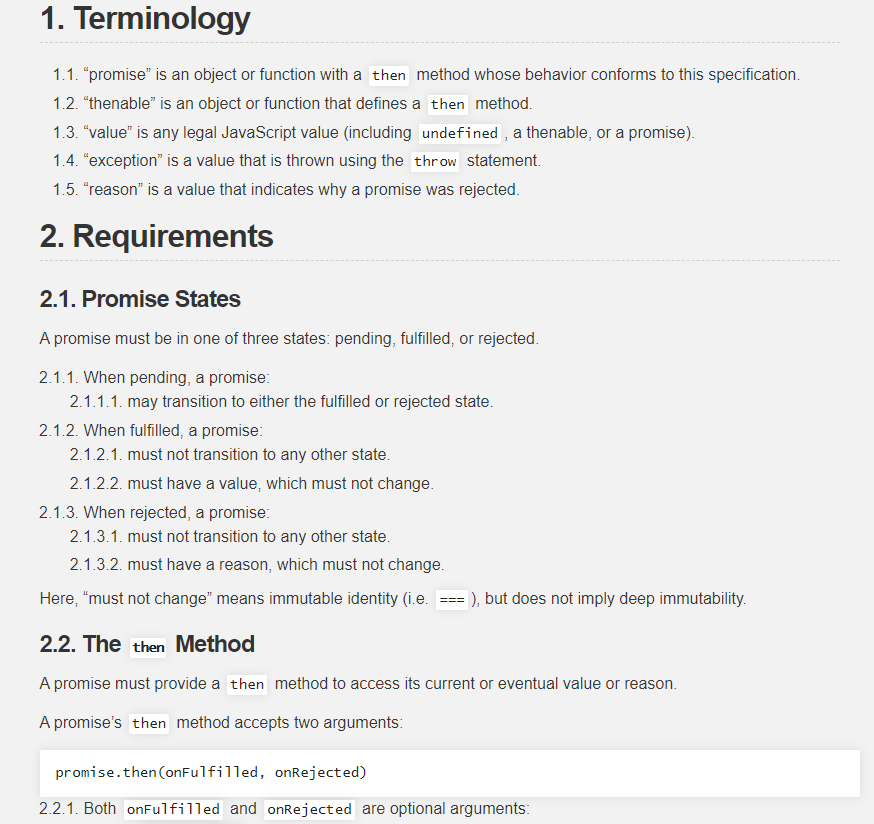
仔细阅读多遍规范之后,我有了一个基本认识,要实现Promise/A+规范,关键是要理清其中几个核心点。
关系链路
本来写了大几千字有点觉得疲倦了,于是想着最后这部分就用文字讲解快速收尾,但是最后这节写到一半时,我觉得我写不下去了,纯文字的东西太干了,干得没法吸收,这对那些对Promise掌握程度不够的读者来说是相当不友好的。所以,我觉得还是先用一张图来描述一下Promise的关系链路。
首先,Promise它是一个对象,而Promise/A+规范则是围绕着Promise的原型方法.then()展开的。
.then()的特殊性在于,它会返回一个新的Promise实例,在这种连续调用.then()的情况下,就会串起一个Promise链,这与原型链又有一些相似之处。“恬不知耻”地再推荐一篇「思维导图学前端 」6k字一文搞懂Javascript对象,原型,继承,哈哈哈。- 另一个灵活的地方在于,
p1.then(onFulfilled, onRejected)返回的新Promise实例p2,其状态转移的发生是在p1的状态转移发生之后(这里的之后指的是异步的之后)。并且,p2的状态转移为Fulfilled还是Rejected,这一点取决于onFulfilled或onRejected的返回值,这里有一个较为复杂的分析过程,也就是后面所述的Promise Resolution Procedure算法。
我这里画了一个简单的时序图,画图水平很差,只是为了让读者们先有个基本印象。
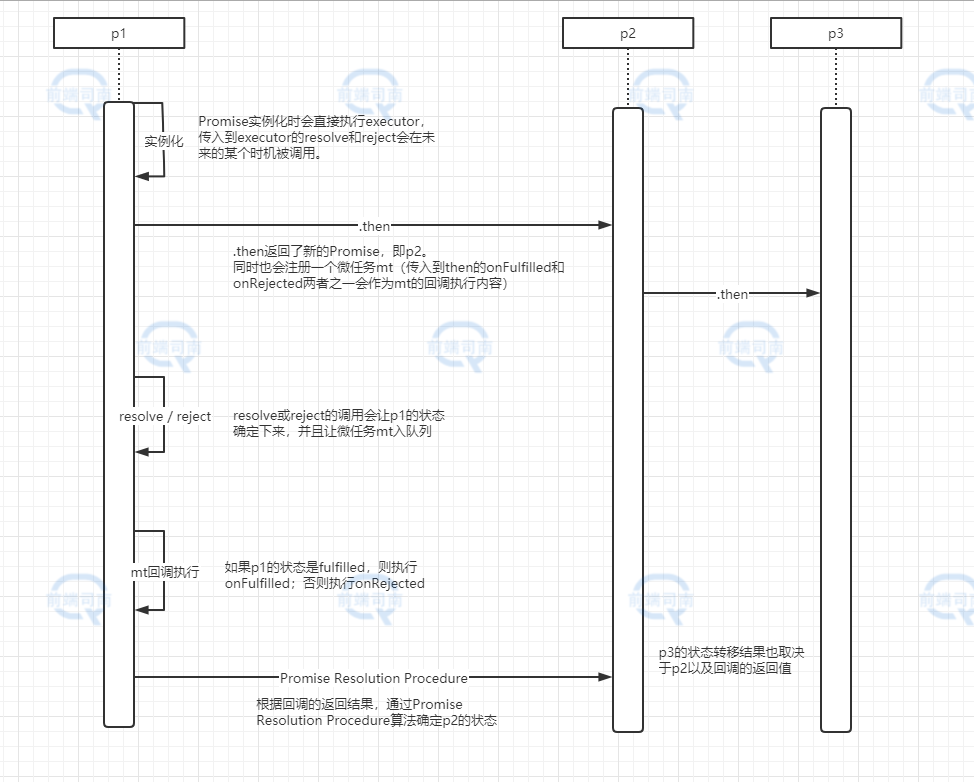
其中还有很多细节是没提到的(因为细节真的太多了,全部画出来就相当复杂,具体过程请看我文末附的源码)。
nextTick
看了前面内容,相信大家都有一个概念,微任务是一个异步任务,而我们要实现Promise的整套异步机制,必然要具备模拟微任务异步回调的能力。在规范中也提到了这么一条信息:
This can be implemented with either a “macro-task” mechanism such as setTimeout or setImmediate, or with a “micro-task” mechanism such as MutationObserver or process.nextTick.
我这里选择的是用微任务来实现异步回调,如果用宏任务来实现异步回调,那么在Promise微任务队列执行过程中就可能会穿插宏任务,这就不太符合微任务队列的调度逻辑了。这里还对Node环境和浏览器环境做了兼容,Node环境中可以使用process.nextTick回调来模拟微任务的执行,而在浏览器环境中我们可以选择MutationObserver。
1 | function nextTick(callback) { |
状态转移
Promise实例一共有三种状态,分别是Pending, Fulfilled, Rejected,初始状态是Pending。
1
2
3
4
5
6
7
8
9
10
11
12const PROMISE_STATES = {
PENDING: 'pending',
FULFILLED: 'fulfilled',
REJECTED: 'rejected'
}
class MyPromise {
constructor(executor) {
this.state = PROMISE_STATES.PENDING;
}
// ...其他代码
}一旦Promise的状态发生转移,就不可再转移为其他状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 封装Promise状态转移的过程
* @param {MyPromise} promise 发生状态转移的Promise实例
* @param {*} targetState 目标状态
* @param {*} value 伴随状态转移的值,可能是fulfilled的值,也可能是rejected的原因
*/
function transition(promise, targetState, value) {
if (promise.state === PROMISE_STATES.PENDING && targetState !== PROMISE_STATES.PENDING) {
// 2.1: state只能由pending转为其他态,状态转移后,state和value的值不再变化
Object.defineProperty(promise, 'state', {
configurable: false,
writable: false,
enumerable: true,
value: targetState
})
// ...其他代码
}
}触发状态转移是靠调用
resolve()或reject()实现的。当resolve()被调用时,当前Promise也不一定会立即变为Fulfilled状态,因为传入resolve(value)方法的value有可能也是一个Promise,这个时候,当前Promise必须追踪传入的这个Promise的状态,整个确定Promise状态的过程是通过Promise Resolution Procedure算法实现的,具体细节封装到了下面代码中的resolvePromiseWithValue函数中。当reject()被调用时,当前Promise的状态就是确定的,一定是Rejected,此时可以通过transition函数(封装了状态转移的细节)将Promise的状态进行转移,并执行后续动作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// resolve的执行,是一个触发信号,基于此进行下一步的操作
function resolve(value) {
resolvePromiseWithValue(this, value)
}
// reject的执行,是状态可以变为Rejected的信号
function reject(reason) {
transition(this, PROMISE_STATES.REJECTED, reason)
}
class MyPromise {
constructor(executor) {
this.state = PROMISE_STATES.PENDING;
this.fulfillQueue = [];
this.rejectQueue = [];
// 构造Promise实例后,立刻调用executor
executor(resolve.bind(this), reject.bind(this))
}
}
链式追踪
假设现在有一个Promise实例,我们称之为p1。由于promise1.then(onFulfilled, onRejected)会返回一个新的Promise(我们称之为p2),与此同时,也会注册一个微任务mt1,这个新的p2会追踪其关联的p1的状态变化。
当p1的状态发生转移时,微任务mt1回调会在接下来被执行,如果状态是Fulfilled,则onFulfilled会被执行,否则onRejected会被执行。微任务mt回调1执行的结果将作为决定p2状态的依据。以下是Fulfilled情况下的部分关键代码,其中promise指的是p1,而chainedPromise指的是p2。
1 | // 回调应异步执行,所以用到了nextTick |
Promise Resolution Procedure算法
Promise Resolution Procedure算法是一种抽象的执行过程,它的语法形式是[[Resolve]](promise, x "[Resolve]"),接受的参数是一个Promise实例和一个值x,通过值x的可能性,来决定这个Promise实例的状态走向。如果直接硬看规范,会有点吃力,这里直接说人话解释一些细节。
2.3.1
如果promise和值x引用同一个对象,应该直接将promise的状态置为Rejected,并且用一个TypeError作为reject的原因。
If
promiseandxrefer to the same object, rejectpromisewith aTypeErroras the reason.
【说人话】举个例子,老板说只要今年业绩超过10亿,业绩就超过10亿。这显然是个病句,你不能拿预期本身作为条件。正确的玩法是,老板说只要今年业绩超过10亿,就发1000万奖金(嘿嘿,这种事期待一下就好了)。
代码实现:
1 | if (promise === x) { |
2.3.2
如果x是一个Promise实例,promise应该采纳x的状态。
2.3.2 If
xis a promise, adopt its state [3.4]:2.3.2.1 If `x` is pending, `promise` must remain pending until `x` is fulfilled or rejected. 2.3.2.2 If/when `x` is fulfilled, fulfill `promise` with the same value. 2.3.2.3 If/when `x` is rejected, reject `promise` with the same reason.
【说人话】小王问领导:“今年会发年终奖吗?发多少?”领导听了心里想,“这个事我之前也在打听,不过还没定下来,得看老板的意思。”,于是领导对小王说:“会发的,不过要等消息!”。
注意,这个时候,领导对小王许下了承诺,但是这个承诺p2的状态还是pending,需要看老板给的承诺p1的状态。
- 可能性1:过了几天,老板对领导说:“今年业务做得可以,年终奖发1000万”。这里相当于p1已经是fulfilled状态了,value是1000万。领导拿了这个准信了,自然可以跟小王兑现承诺p2了,于是对小王说:“年终奖可以下来了,是1000万!”。这时,承诺p2的状态就是fulfilled了,value也是1000万。小王这个时候就“别墅靠海”了。

- 可能性2:过了几天,老板有点发愁,对领导说:“今年业绩不太行啊,年终奖就不发了吧,明年,咱们明年多发点。”显然,这里p1就是rejected了,领导一看这情况不对啊,但也没办法,只能对小王说:“小王啊,今年公司情况特殊,年终奖就不发了。”这p2也随之rejected了,小王内心有点炸裂……

注意,Promise /A+规范2.3.2小节这里有两个大的方向,一个是x的状态未定,一个是x的状态已定。在代码实现上,这里有个技巧,对于状态未定的情况,必须用订阅的方式来实现,而.then就是订阅的绝佳途径。
1 | else if (isPromise(x)) { |
多的细节咱这篇文章就不一一分析了,写着写着快1万字了,就先结束掉吧,感兴趣的读者可以直接打开源码看(往下看)。
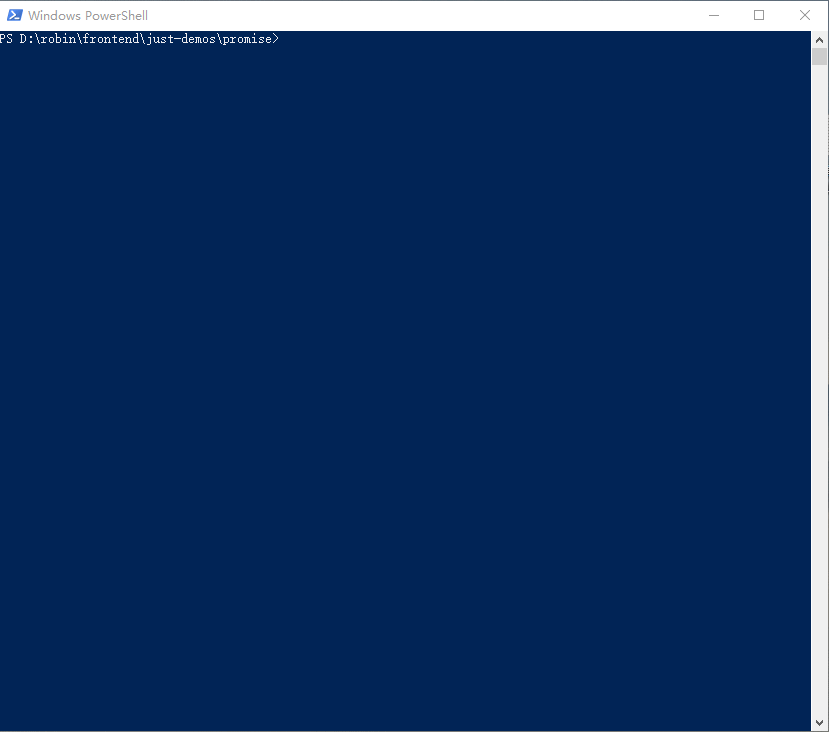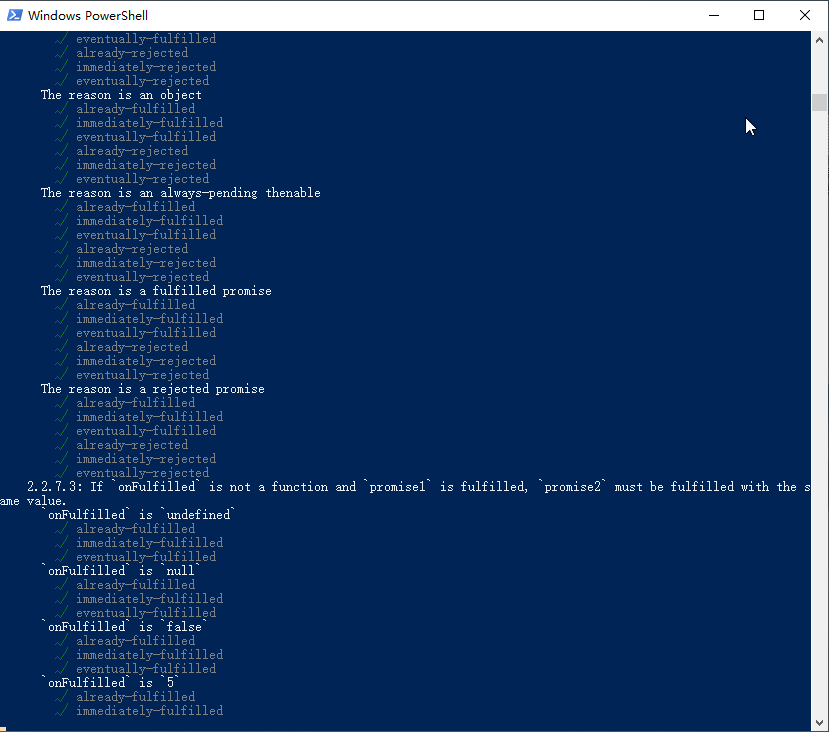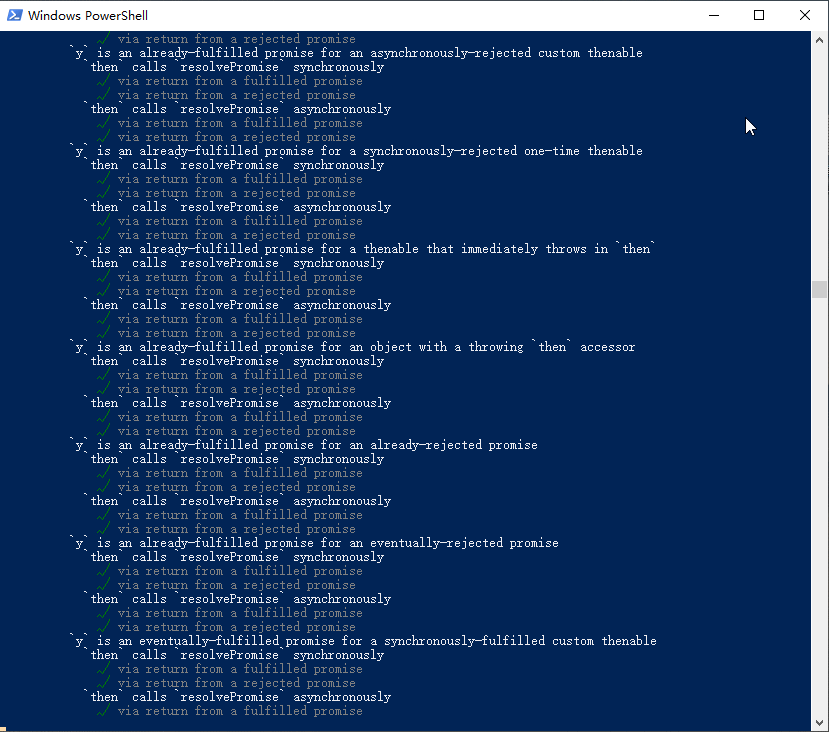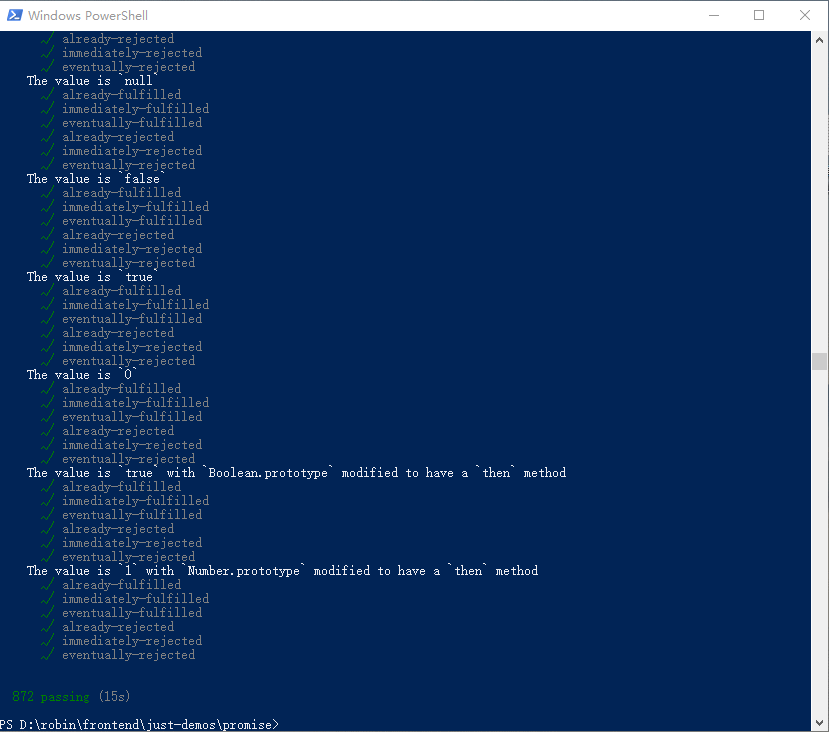
这是跑测试用例的效果图,可以看到,872个case是全部通过的。
完整代码
这里直接给出我写的Promise/A+规范的Javascript实现,供大家参考。后面如果有时间,会考虑详细分析下。
- github仓库:promises-aplus-robin(顺手点个star就更好了)
- 源码
- 源码注释版
缺陷
我这个版本的Promise/A+规范实现,不具备检测execution context stack为空的能力,所以在细节上会有一点问题(execution context stack还未清空就插入了微任务),无法适配上面那道「浏览器不讲武德?」的题目所述场景。
方法论
不管是手写实现Promise/A+规范,还是实现其他Native Code,其本质上绕不开以下几点:
- 准确理解Native Code实现的能力,就像你理解一个需求要实现哪些功能点一样,并确定实现上的优先级。
- 针对每个功能点或者功能描述,逐一用代码实现,优先打通主干流程。
- 设计足够丰富的测试用例,回归测试,不断迭代,保证场景的覆盖率,最终打造一段优质的代码。
总结
看到结尾,相信大家也累了,感谢各位读者的阅读!希望本文对宏任务和微任务的解读能给各位读者带来一点启发。Promise/A+规范总体来说还是比较晦涩难懂的,这对新手来说是不太友好的,因此我建议有一定程度的Promise实际使用经验后再深入学习Promise/A+规范。通过学习和理解Promise/A+规范的实现机制,你会更懂Promise的一些内部细节,对于设计一些复杂的异步过程会有极大的帮助,再不济也能提升你的异步调试和排错能力。
这里还有一些规范和文章可以参考:
- Promises/A+规范
- Event Loop Processing Model
- tasks-microtasks-queues-and-schedules
- Jobs and Host Operations to Enqueue Jobs




